개요
스터디 그룹 매칭 서비스 StudyHub를 진행하며 아쉬웠던 점을 하나 꼽자면 검색 기능입니다.
사용자 입장에서 생각했을 때 '정보처리기사' 모집 게시글을 업로드한다면 동일한 스터디에서도 아래와 같이 많은 게시글이 생성될 수 있습니다.
'정보처리기사 스터디원 구합니다.'
'꾸준히 진행할 스터디 구합니다. (정보처리기사)'
프로젝트에서 조회 시 성능을 위해 인덱스를 사용했기 때문에 '정보처리기사' 라고 검색했을 시 첫 번째 게시글만 검색되고 두번째 게시글은 검색이 안된다는 단점이 있었습니다.
물론 아직 데이터가 적기 때문에 '%검색문자열%' 과 같이 양쪽에 와일드카드를 삽입하는 방법이 있습니다.
하지만 추후 데이터가 많아졌을때를 대비하여 N-gram 파서를 이용해 검색 기능을 향상시켜보겠습니다.
FullText-Index 구조
n-gram 파서를 사용하기전에 기반이 되는 인덱스인 full-text-index에 대해 알아보겠습니다.
full text index에 사용되는 데이터 구조는 역 인덱스입니다. 역 인덱스는 인덱스에서 지원하기 어려운 검색 조건을 지원하기 위해 특정 컬럼의 데이터를 파싱하여 각 단어가 속한 문서의 ID를 저장하는 방식으로 구현되었습니다.
아래 문자열에 대해 FullText-Index를 생성해보겠습니다.
'정보처리기사 스터디원 구합니다.', Document Id == 1
'꾸준히 진행할 스터디 구합니다. (정보처리기사)', Document Id == 2
'서울 광진구 정보처리기사 급구', Document Id == 3
| Dictionary | Frequency | Document ID |
| 정보처리기사 | 3 | 1, 2, 3 |
| 스터디원 | 1 | 2 |
| 꾸준히 | 1 | 2 |
| 광진구 | 1 | 1 |
공백문자 기준으로 단어를 분리한 뒤, 각 단어별로 인덱스를 생성했기 때문에 "정보처리기사"를 검색했을 때 문자열 맨 앞에 "정보처리기사"가 없더라도 인덱스를 이용한 검색이 가능합니다.
n-gram
전문 검색에서 n-gram은 주어진 문자열에서 n개 문자의 인접한 순서입니다. 예를들어 n-gram 을 이용해 '정보처리기사' 문자열을 다음과 같이 토큰나이즈합니다.
| N = 1 | '정', '보', '처', '리', '기', '사' |
| N = 2 | '정보', '보처', '처리', '리기', '기사' |
| N = 3 | '정보처', '보처리', '처리기', '리기사' |
| N = 4 | '정보처리', '보처리기', '처리기사' |
ngram 파서는 내장된 서버 플러그인이기 때문에 서버가 시작되면 자동으로 로드됩니다. 그렇기에 아래와 같은 방식으로 간단하게 테이블에 적용할 수 있습니다.
CREATE TABLE articles
(
FTS_DOC_ID BIGINT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(100),
FULLTEXT INDEX ngram_idx(title) WITH PARSER ngram
) Engine=InnoDB CHARACTER SET utf8mb4;
# 이미 생성된 테이블에 적용할 때
ALTER TABLE articles ADD FULLTEXT INDEX ngram_idx(title) WITH PARSER ngram;
WITH PARSER ngram을 보시면 ngram 생성 과정에서 ngram의 값을 지정해주지 않으면 값이 자동으로 2로 초기화됩니다.
성능 테스트
기존 프로젝트에 더미데이터 20만개를 넣어 FullText-Index를 적용하기 전과 후의 성능을 비교해보겠습니다.

n-gram 파서 적용 전
소요시간 평균 : 190ms
가져온 데이터 수 : 3319개
n-gram 파서 적용 후
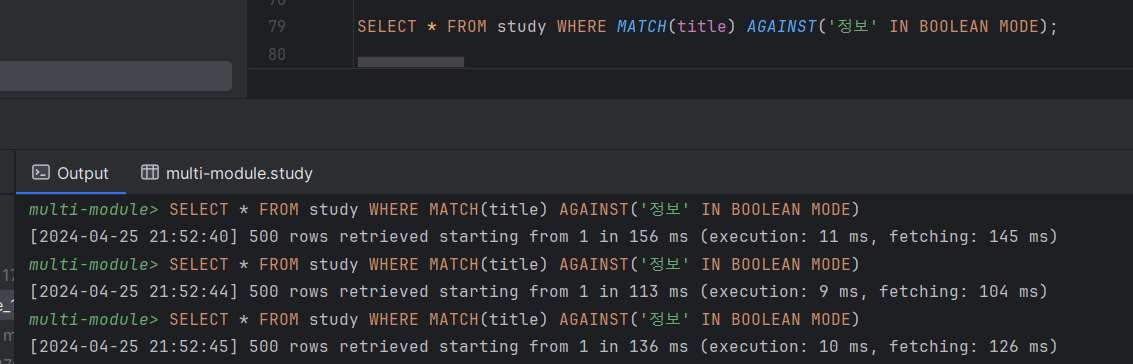
소요시간 평균 : 10ms
가져온 데이터 수 : 3319개
20만개의 데이터에 대해서 적용 전은 평균 190ms, 적용 후는 9ms가 소요되어 약 21배의 성능 차이를 보였습니다.
explain analyze 키워드를 통해 쿼리 실행계획을 확인해보겠습니다.
n-gram 파서 적용 전
-> Filter: (study.title like '%정보%') (cost=19704 rows=20491) (actual time=188..379 rows=3319 loops=1)
-> Table scan on study (cost=19704 rows=184437) (actual time=0.105..312 rows=200010 loops=1)
n-gram 파서 적용 후
-> Filter: (match study.title against ('정보' in boolean mode)) (cost=0.67 rows=1) (actual time=0.872..15 rows=3319 loops=1)
-> Full-text index search on study using ngram_idx (title='정보') (cost=0.67 rows=1) (actual time=0.869..14.6 rows=3319 loops=1)
예상대로 전자는 테이블 내 모든 데이터(20만개)를 탐색하며 '정보' 문자열을 가지고 있는지 검증한 후 데이터를 가져오고 있습니다.
후자의 경우 Full-text index에 저장된 Id값(3319개)만을 이용해서 데이터를 가져오고 있습니다.
n-gram의 한계
위에서 말씀드린대로 ngram 파서의 n의 기본값은 2로 설정되어있습니다.
이 때문에 '정보처리기사' 라고 검색할 시 '정보' 이외에도 '보처', '처리', '리기', '기사' 문자열을 가진 데이터들이 모두 검색된다는 치명적인 단점이 있었습니다.
이 경우 n-gram 파서를 이용하기 보단 아래 쿼리문을 이용해 공백 기준으로 인덱스를 생성하는 편이 더 좋지 않을까 생각됩니다.
ALTER TABLE study ADD FULLTEXT(title);
'개발 > Database' 카테고리의 다른 글
| MySQL InnoDB B-Tree Index 탐색 과정 분석 (0) | 2024.04.11 |
|---|---|
| Hash 조인, NL 조인 (2) | 2024.02.16 |
| [StudyHub] 성능 관점에서 확인해본 조회 쿼리문 (0) | 2024.02.11 |
| [StudyHub] 다중 칼럼 인덱스를 이용한 조회 성능 개선 (0) | 2024.01.12 |
| [StudyHub] FK 매핑으로 인한 외래키 참조 무결성 문제 해결 (2) | 2024.01.01 |



