서론
8만건의 데이터를 조회할 때 평균 95ms의 성능이 나왔기때문에 개선해보고자 한다.
개선하려는 쿼리문은 아래와 같다.
SELECT p.post_id, p.major, p.study_start_date, p.study_end_date, u.email, u.image_url
FROM post as p
LEFT JOIN users as u on p.posted_user_id = u.user_id
ORDER BY p.remaining_seat asc, p.created_date desc
LIMIT 10 offset 5;
검색 조건은 로그인을 하지 않은 상태로 인기순, 생성날짜(나중에 생성한 날짜가 우선)로 정렬한 전체 데이터를 5 페이지 기준 상위 10개의 데이터를 가져오는 조건이다.
성능 테스트
테이블마다 데이터를 8만개 삽입한 뒤 조회 요청을 보내니 앞서 얘기했던것과 같이 평균 95ms 가 소요되었다.



쿼리문에 EXPLAIN ANALYZE를 붙여 옵티마이저의 쿼리 실행 순서를 확인해보겠다.

1. 'post' 테이블 전체 스캔
2. 스캔된 데이터를 remaining_seat 오름차순, created_date 내림차순으로 정렬
3. Nested loop left join : 'post' 테이블과 'users' 테이블을 LEFT JOIN
4. 'users' 테이블에서 'post' 테이블의 posted_user_id와 일치하는 user_id를 기본 키(PRIMARY)로 사용하여 인덱스 조회를 수행
5. 최종적으로 반환된 결과 중 10개를 반환
실행 계획으로 보아 부하가 발생할 여지는 두가지 존재한다.
1. users 테이블과 post 테이블 join으로 인한 오버헤드
2. 인기순, 생성날짜 정렬로 인한 오버헤드
Join
users와 post가 join 할 때 users 테이블의 PK를 이용해 join 하기 때문에 클러스터 인덱스를 타면서 join 하게 되고 이는 O(5 * 10^5 * log10^5) 의 시간 복잡도를 가질 것으로 예상되기 때문에 큰 부하를 주지 않는다.
정확한 확인을 위해 쿼리문에 EXPLAIN을 추가해 쿼리의 실행계획을 살펴보았다.

예상한대로 클러스터 인덱스를 이용해 join 하고 있다.
ORDER BY
Join에서 부하가 발생하지 않는것으로 미루어보아 정렬에서 부하가 발생할 것으로 예상된다.
쿼리문에서 정렬 조건을 주석처리하고 실행한 뒤 성능을 측정해보겠다.
select p.post_id, p.major, p.study_start_date, p.study_end_date, u.email, u.image_url
from post as p
left join users as u on p.posted_user_id = u.user_id
# order by p.remaining_seat asc, p.created_date desc
limit 10
offset 50;


정렬 조건을 주석처리하니 쿼리 성능이 2.7배 개선되었다.
정렬 과정에서 성능이 크게 떨어진다는 파악했기 때문에 다중 칼럼 인덱스를 이용해 정렬 성능을 올려보겠다.
다중 칼럼 인덱스를 이용한 ORDER BY 성능 개선
MySQL 버전 8.0 부터 복합 인덱스 생성 시 각 칼럼마다 별도로 정렬 순서를 지정할 수 있게 되었기 때문에 쿼리문과 같이 remaining_seat는 오름차순, created_date는 내림차순으로 인덱스를 지정했다.

remaining_seat, created_date로 인덱스를 생성하고 성능을 테스트해본 결과 평균 35ms 의 응답시간이 측정되었다.



인덱스하지 않았을 때 보다 약 2.7배의 성능이 증가한 것이다.
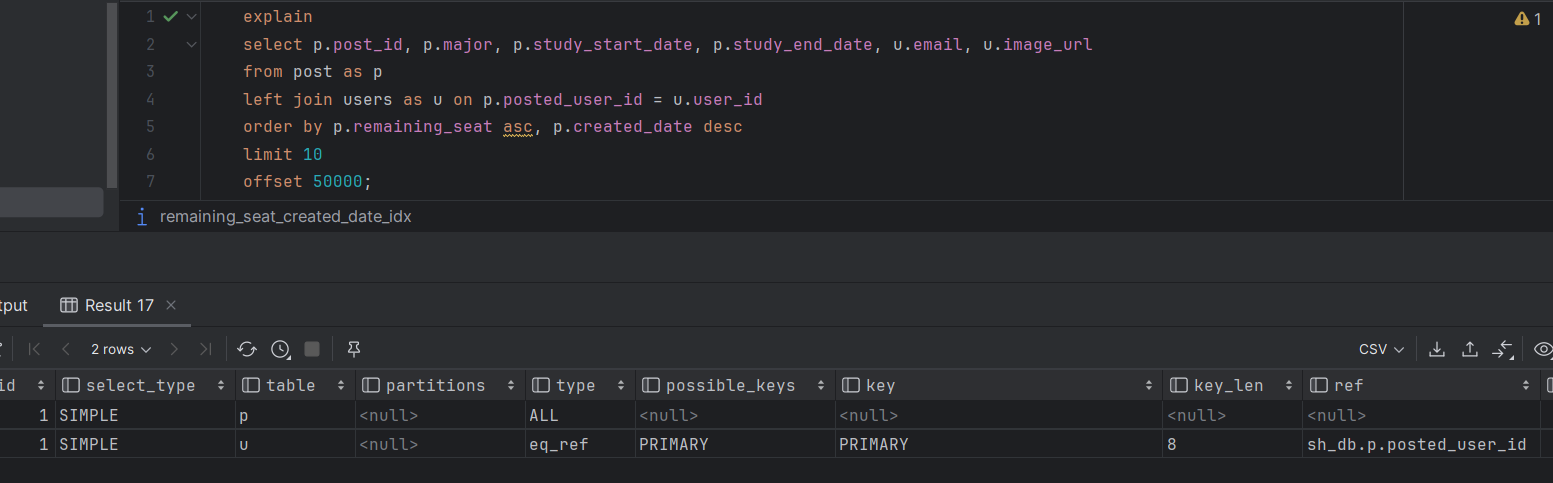
EXPLAIN 키워드를 통해 쿼리문이 인덱스를 잘 타고있는지 확인해보겠다.

key 칼럼이 이전에 생성한 remaining_seat_created_date_idx 로 지정됐고 type이 index가 된 것으로 보아 인덱스를 이용해 조회하고 있다.
결론
다중 칼럼 인덱스를 이용한 정렬로 조회 성능을 향상시켜보았다.
지금은 WHERE 절의 조건이 없기 때문에 인덱스를 이용해 정렬된 데이터를 순차적으로 그대로 가져오면 된다. 하지만 조건이 추가될 경우 생성한 멀티칼럼 인덱스에서 WHERE 조건절에 해당하는 데이터를 찾기위해 인덱스 풀 스캔을 돌리기 때문에 랜덤 IO로 인한 성능 저하 문제가 발생할 수 있다.
이는 아래 포스트에서 개선 방법을 정리했기때문에 참고하면 좋을 것 같다.
[StudyHub] 성능 관점에서 확인해본 조회 쿼리문
서론 RealMySQL 8.0을 읽으면서 프로젝트에서 작성한 대부분의 쿼리문들이 성능을 염두해두지 않고 작성했다는 것을 알았다. 지금은 데이터 수가 적기 때문에 괜찮지만 추후 데이터 수가 많아졌을
liljay.tistory.com
또한 인덱스를 생성해도 쿼리문에서 OFFSET을 크게 잡을 경우 랜덤 IO가 증가해 성능이 저하되기 때문에 옵티마이저에서 인덱스를 이용하지 않고 테이블 full scan 해서 데이터를 반환한다.
이 문제는 NO OFFSET을 사용하는 방식으로 추후 개선해보겠다.
'개발 > Database' 카테고리의 다른 글
| MySQL InnoDB B-Tree Index 탐색 과정 분석 (0) | 2024.04.11 |
|---|---|
| Hash 조인, NL 조인 (2) | 2024.02.16 |
| [StudyHub] 성능 관점에서 확인해본 조회 쿼리문 (0) | 2024.02.11 |
| [StudyHub] FK 매핑으로 인한 외래키 참조 무결성 문제 해결 (2) | 2024.01.01 |
| DB 인덱싱 성능 테스트 (2) | 2023.12.04 |



